MCRouter笔记(二) 常见应用
-
分片池
当数据量太大,单个memcached不够放时,通常会把数据拆分到多台机器上,这就是所谓的水平分割。mcrouter提供了一个行之有效的consistent hashing算法(furc_hash),算法允许给多个memcached实例分配哈希值。Hostname hashing再根据分配的哈希值为客户端选择一个独一无二的副本,在特定的应用中有很多其他的有用的散列方法。
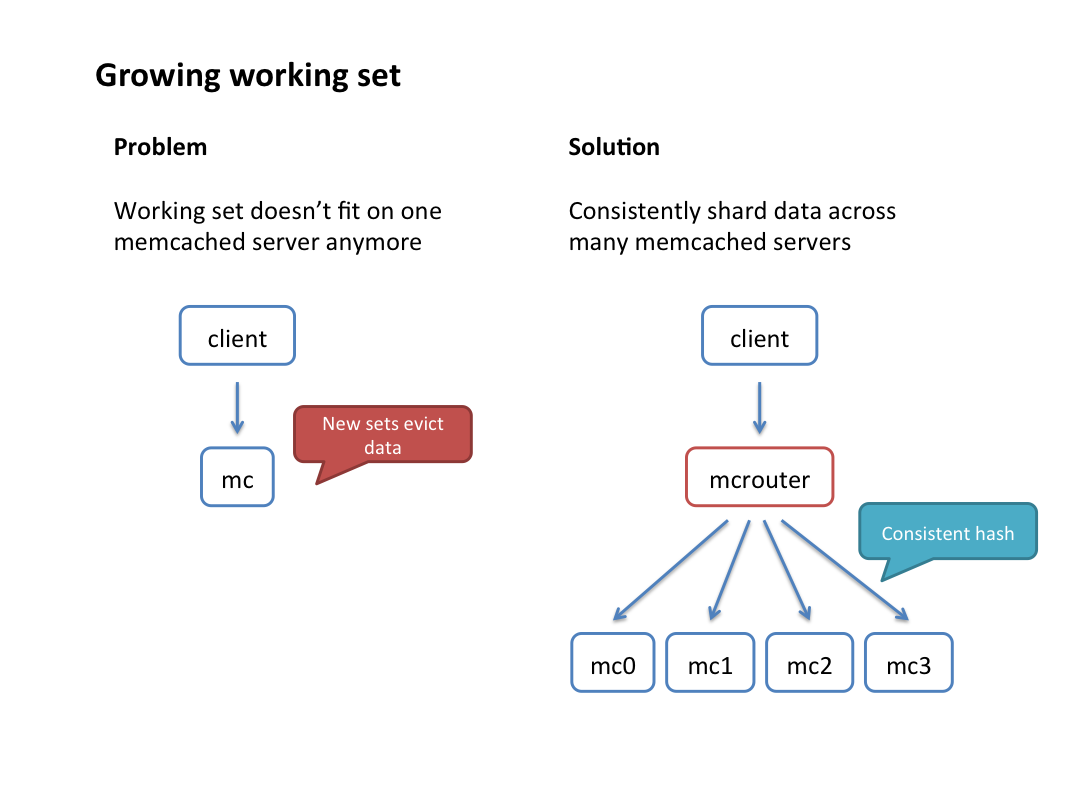
分片池
配制说明:请求按hash key路由到池A中不同的memcached。
{
"pools": {
"A": {
"servers": [
// your destination memcached boxes here, e.g.:
"127.0.0.1:12345",
"[::1]:12346"
]
}
},
"route": "PoolRoute|A"
}
-
池备份
在多个主机上保存一份相同数据的备份,set和delete时向所有的主机写入同一份数据,但是get时随机从缓存读取一份数据。这样就可以处理由于主机数据的限制造成分片池不能处理的读出率的问题;而且还能增强数据的可用性(比如:由于故障自动转移,即使一份备份坏掉也不会影响其正常操作)。
池备份适用于get操作远远大于set和delete的场景,mcrouter下的效果:
- get操作随机到一个memcached,如果请求失败,从其它memcached再次请求,可以设置失败重试次数。
- set和delete操作发到所有服务器。
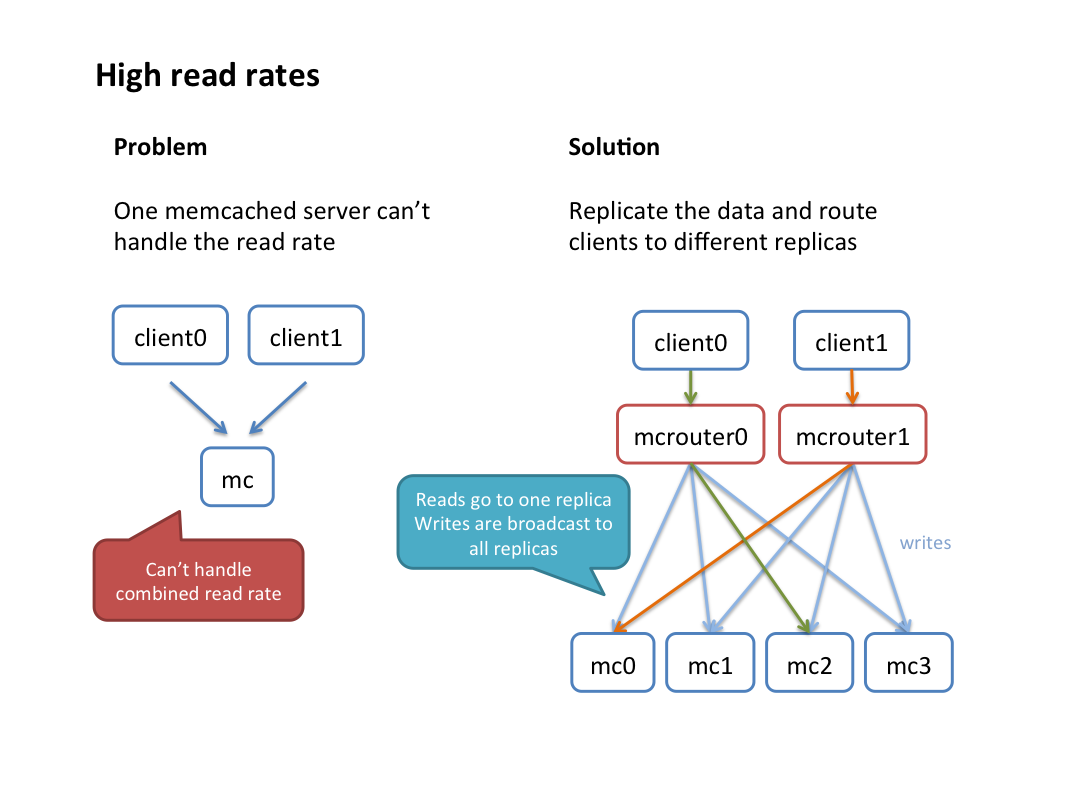
池备份
配制说明:adds、deletes和sets被发送到所有池A中的机器,gets被随机发送,如果一个get请求失败,它会自动发送(重试)到另一台主机池,缺省情况下重试5次。
{
"pools": {
"A": {
"servers": [
// hosts of replicated pool, e.g.:
"127.0.0.1:12345",
"[::1]:12346"
]
}
},
"route": {
"type": "OperationSelectorRoute",
"operation_policies": {
"add": "AllSyncRoute|Pool|A",
"delete": "AllSyncRoute|Pool|A",
"get": "LatestRoute|Pool|A",
"set": "AllSyncRoute|Pool|A"
}
}
}
-
前缀路由
mcrouter可以根据key前缀把客户端分配到不同的memcahed池.比如,你可以把以”foo”为前缀的所有key分配到一个“foo”池,把以”bar”为前缀的所有key分配到另外一个”bar”池,其他的key都分配到”wildcard” 池,这是一种简单的均衡负载的方法。
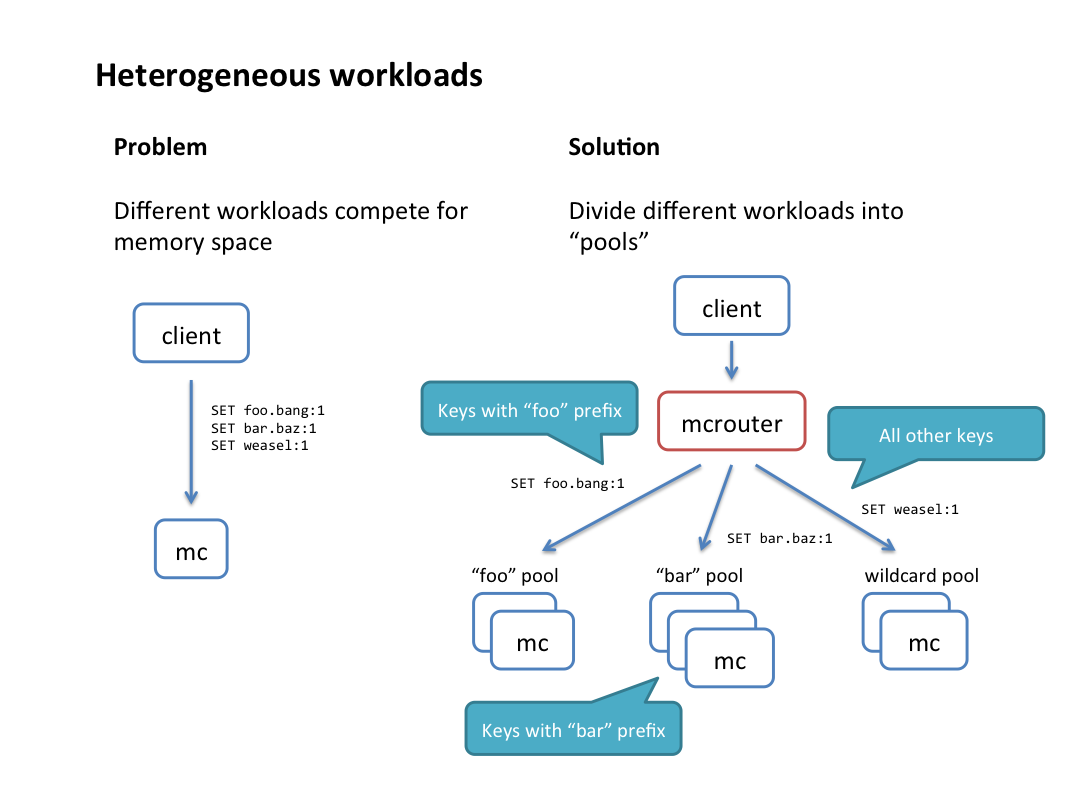
前缀路由
配制说明:”a”前缀的所有key分配到’workload1’,”b”前缀的所有key分配到’workload2’,其它分配到’common_cache’。
{
"pools": {
"workload1": { "servers": [ /* list of cache hosts for workload1 */ ] },
"workload2": { "servers": [ /* list of cache hosts for workload2 */ ] },
"common_cache": { "servers": [ /* list of cache hosts for common use */ ] }
},
"route": {
"type": "PrefixSelectorRoute",
"policies": {
"a": "PoolRoute|workload1",
"b": "PoolRoute|workload2"
},
"wildcard": "PoolRoute|common_cache"
}
}
-
自动填充新增缓存
mcrouter通过指定的”warm”缓存区主动填充新增的缓存区域的方式来消除新增缓存区造成的性能影响。
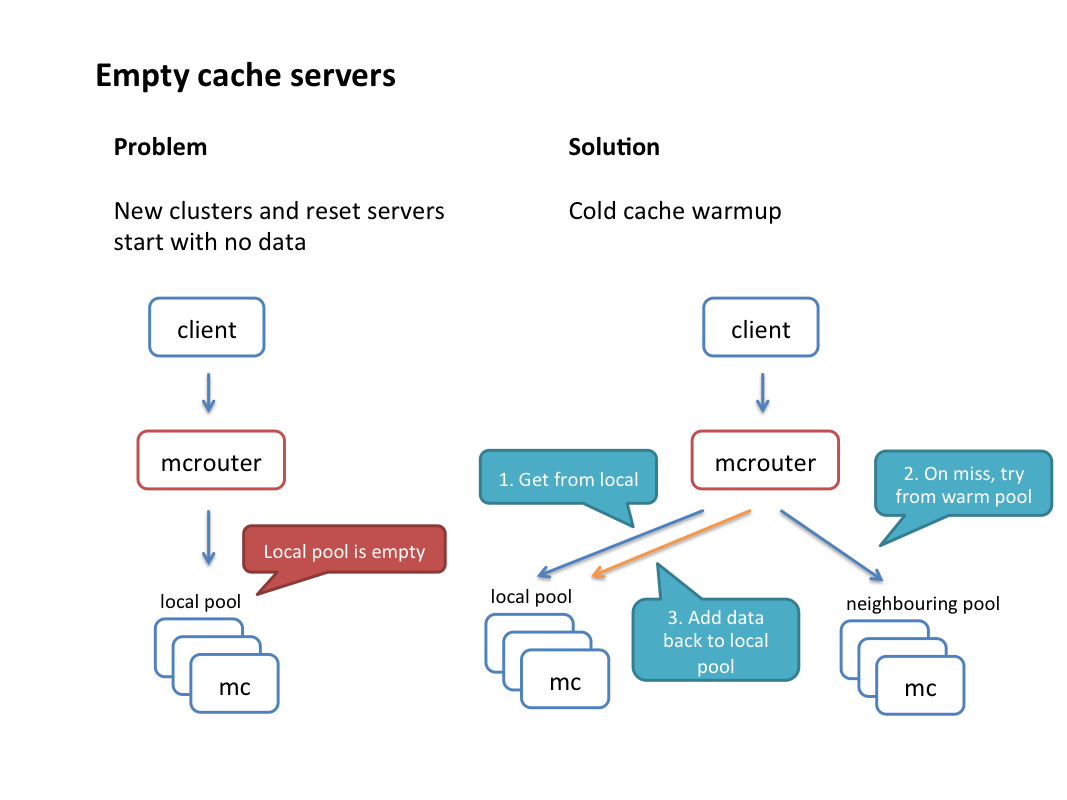
配制说明:所有的sets和deletes路由到”clod”,当从get cold没有命中,就去遍历warm,如果warm返回命中就返回给客户端并发起异步请求更新cold。
{
"pools": {
"cold": { "servers": [ /* cold hosts */ ] },
"warm": { "servers": [ /* warm hosts */ ] }
},
"route": {
"type": "WarmUpRoute",
"cold": "PoolRoute|cold",
"warm": "PoolRoute|warm"
}
}